I recently started using ghost.io to host this blog. I really like being able to use markdown to author my posts, and the image upload experience is nice. Ghost uses Handlebars as its templating engine, which was easy enough to pick up.
One thing that is missing, however, is a search function. The suggested alternatives were Google custom search or Swiftype. The Google experience immediately turned me off, as it has Google branding by default. And I did not see any easy way to influence the search results with "best bets" or facets. (I'm not saying it is not offered, just that I didn't find it in my cursory review.) Swiftype is not a free service. (I am paying for Ghost Pro, but $14/month for search was too steep for a blog with a bunch of articles.)
As I considered what I wanted to do, I remembered that Azure provides a search service. Like most things Azure, I can start on a free tier and scale up if necessary. So, that is what I did.
Azure Search
Rather than duplicate the Azure Search documentation let me summarize:
- Create an index.
- Define the schema of objects that will be in that index.
- Upload "documents" into the index. Documents in this context are JSON objects.
So, I need to push my content into the index. The Azure Search SDK is in preview, but it is not terribly complicated. I'll keep my eye on it and once ready I will move my code to a WebJob. What code you ask? Well code that reads my Ghost content and adds it to the index.
I started with the sample application provided in the Azure documentation. The changes necessary for my content are quite simple.
Azure Index
In my Azure index, I want the post content to be searchable. I need the URL so that my results can include the link. And I need a unique identifier so that any future processing can update existing documents. Long-tem, I want the publish date and tags so that I can have facets or refiners in my search results. The index and its schema can be created in the Azure Portal, but the sample application had a method to do so. I made changes to match my schema.
private static void CreateIndex(SearchServiceClient serviceClient)
{
var definition = new Index()
{
Name = "posts",
Fields = new[]
{
new Field("guid", DataType.String) { IsKey = true },
new Field("title", DataType.String) { IsSearchable = true, IsFilterable = true, IsRetrievable=true },
new Field("content", DataType.String) { IsSearchable = true },
new Field("description", DataType.String) { IsRetrievable=true },
new Field("link", DataType.String) { IsRetrievable=true },
new Field("category", DataType.Collection(DataType.String)) { IsSearchable = true, IsFilterable = true, IsFacetable = true },
new Field("pubDate", DataType.DateTimeOffset) { IsFilterable = true, IsRetrievable=true, IsSortable = true, IsFacetable = true },
}
};
serviceClient.Indexes.Create(definition);
}
Ghost Content
I have two options for getting Ghost content. I can export from the administration page, or I can read the RSS feed. The only problem with the RSS option is that the feed will not include "static" pages in Ghost. (In my site, all the links on the "Articles" page are static pages.) But, since I write articles less frequent than posts, I can live with the need to run a push process manually once the article is published.
So, reading the Ghost export via C#:
private static void UploadDocuments(SearchIndexClient indexClient)
{
List<GhostPost> documents = new List<GhostPost>();
dynamic data = JObject.Parse(File.ReadAllText(@"schaeflein-consulting.ghost.2016-02-02.json"));
foreach (var item in data.db[0].data.posts)
{
HtmlDocument html = new HtmlDocument();
html.LoadHtml((string)item.html);
string content = ExtractViewableTextCleaned(html.DocumentNode);
documents.Add(new GhostPost
{
Guid = item.uuid,
Title = item.title,
Content = content,
Link = String.Format("http://www.schaeflein.net/{0}", item.slug),
PubDate = item.published_at
});
}
try
{
var batch = IndexBatch.MergeOrUpload<GhostPost>(documents);
indexClient.Documents.Index(batch);
}
catch (IndexBatchException e)
{
Console.WriteLine("Failed to index some of the documents: {0}",
String.Join(", ", e.IndexingResults.Where(r => !r.Succeeded).Select(r => r.Key)));
}
}
As I mentioned, I want my content in the index. And, I want search results to include a snippet of the content including hit highlights. One little glitch -- the content in Ghost is HTML. When Azure returns the content, they inject an <em> tag around the search term. From an HTML perspective, that could be a problem. For example, if the search term is part of the post URL, then we get a result that has this:
<a href="/setting-status-in-<em>workflow</em>">Setting Status in <em>Workflow</em></a>
So, I want to strip the HTML from the post content before i push it into the index. I used the HTML Agility Pack along with sample code from Mattias Fagerlund to pull the viewable text from the content HTML. That is the ExtractViewableTextCleaned method in the above snippet.
Ghost Content from RSS
Reading RSS is also quite simple thanks to the community. Mads Kristensen published a Simple RSS reader class in c# that takes care of RSS. I only need to copy the data into my GhostPost object and send it along to Azure.
private static void IndexFromRss(SearchIndexClient indexClient)
{
List<GhostPost> documents = new List<GhostPost>();
RssReader rssReader = new RssReader("http://www.schaeflein.net/rss");
var posts = rssReader.Execute();
foreach (var post in posts)
{
HtmlDocument html = new HtmlDocument();
html.LoadHtml(post.Content);
string content = ExtractViewableTextCleaned(html.DocumentNode);
documents.Add(new GhostPost
{
Guid = post.Id,
Title = post.Title,
Content = content,
Description = post.Description,
Link = post.Link,
PubDate = post.Date
});
}
try
{
var batch = IndexBatch.MergeOrUpload<GhostPost>(documents);
indexClient.Documents.Index(batch);
}
catch (IndexBatchException e)
{
Console.WriteLine("Failed to index some of the documents: {0}",
String.Join(", ", e.IndexingResults.Where(r => !r.Succeeded).Select(r => r.Key)));
}
}
Searching the index
Azure Search has a REST API that allows us to perform searches. Since my blog is hosted, I have to use AJAX in the browser to execute searches. Running script from my blog domain that calls out to Azure will have cross-origin issues. Fortunately, Azure provides for this. The Index settings in Azure have a "CORS Options" property, in which a list of allowed domains can be provided.
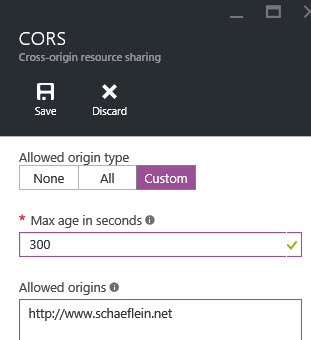
With the cross-domain options set, I can query the index. I use the REST interface, specifying the highlight options I want:
https://<azure-account>.search.windows.net/indexes/posts/docs?&highlight=content&highlightPreTag=%3Cspan style="background:yellow;"%3E&highlightPostTag=%3c/span%3E&search=' + searchTerm
The querystring parameters I use:
| parameter=value | description |
|---|---|
| highlight=content | Only provide hit highlists from my content field |
| highlightPreTag=%3Cspan style="background:yellow;"%3E | Wrap the hit hightlight in a SPAN tag, with the background color set to yellow. |
| highlightPostTag=%3C/span%3E | Close the SPAN tag |
The call to Azure search returns a json data packet, which I enumerate and add to the page with the appropriate HTML:
for(var i = 0; i < posts.length; i++) {
var p = posts[i];
var date = new Date(p.pubDate);
var dateStr = date.getDate() + ' ' + months[date.getMonth()] + ' ' + date.getFullYear();
var $a = $('<a class="article-link" href="' + p.link + '"><article class="box is-link"><header class="post-header"><h2 class="post-title">' + p.title + '</h2></header> <section class="post-excerpt"><p>' + p["@search.highlights"].content[0] + '...</p></section><footer class="post-meta"><time class="post-date" datetime="' + p.pubDate + '">' + dateStr + '</time></footer></article></a>');
if(i == posts.length) {
$a.addClass('last');
}
$parent.append($a);
}
The result is basic search capability. When time allows, I plan to include other features of Azure Search. I do not expect it to match what we can do in SharePoint 2013, but I believe we can get pretty close.